分享程序员开发的那些事...
更新时间:2022-09-16 18:07:31
注:本文为YIG团队原创
1. Yet Another Index Gateway
YIG是S3协议兼容的分布式对象存储系统。它脱胎于开源软件ceph,在多年的商业化运维中,针对运维中出现的问题和功能上的新需求,重新实现了一遍radosgw用于解决以下问题:
1) 单bucket下面文件数目的限制
2) 大幅度提高小文件的存储能力
3) bucket下面文件过多时,list操作延迟变高
4) 后台ceph集群在做recovery或者backfill时极大影响系统性能
5) 提高大文件上传并发效率
2. Ceph对象存储遇到的挑战
本文假设读者已经对ceph,ceph/radosgw或者分布式系统,和S3 API有所了解。在这里不会详细介绍他们的特点和架构。
如果有不清楚的同学建议到ceph的官网了解一下。S3 API可以参考Amazon S3。
另外对象存储都是大容量的情况,同时本文也默认所有存储介质都是普通的机械硬盘。其主要特点就是:顺序IO快,随机IO特别慢。2.1 Ceph Radosgw对象存储系统
radosgw的架构如图
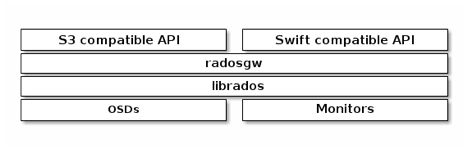
radosgw充分利用了librados底层的4类API完成数据存储的目的,实际上radosgw用的是C++ API,但是这里我们使用C API便于说明问题
1)rados_read/rados_write 这组API主要用来存储对象的实际内容,他会根据用户对象的名称生产oid,然后映射到多个osd上,然后写入实际数据,比较简单,对应于rados命令行的
"rados put / get"
2) rados_write_op_omap_set / rados_read_op_omap_get_vals 这组API主要用来存储bucket的元数据。每个ceph osd在初始化的时候会生产一个嵌入式的数据库。(filestore对应leveldb,bluestore对应rocksdb。 通过这组API可以给object设置key-value值,这组API在radosgw里面主要存储重要的bucket下有哪些文件。比如S3里面有一个bucket叫document,里面有3个文件,名字分别是: A、B、C ,那么对应的在.rgw.index的pool里面会有一个document.XXXX,这里面的XXXX是bucket的instance ID,他的omap对应的就是
KEY VALUE
A value
B value
C value
在ceph的J版本之前,bucket下的文件列表都是由一个object对应的omap记录的,在后续的版本中加入bucket sharding的功能,让文件列表可以由多个嵌入式KV存储记录。
3) rados_getxattrs/rados_setxattrs这个API主要存储每个对象的元数据,包括每个分片的信息、ACL、contentType,这些信息都用这组API存储和读取。它们对应的就是filestore的xfs使用的xattrs,或者bluestore的rocksdb里面的kv对。
4) rados_exec
参考文档cls,传统上增删改查的操作并不一定满足所有需求。比如需要一个计数器,原子的记录一个object访问次数;或者需要在osd上计算一个object的md5,而不需要下载到客户端再进行计算。所有的cls操作都是对一个object原子的。用户可以自己编写cls plugins,在osd启动的时候加载。之前只能用c++写,现在从J版本以后开始支持用lua写的plugin了。radosgw使用这个API做原子的操作,或者记录日志。2.2 为什么radosgw存储小文件会有性能问题
从上面的rados存储原理可以看到,要在一个S3兼容的系统里存储数据,它需要存储
1) 数据本身
2) 元数据(ACL、contentType、分片信息)
3) 修改bucket的元数据(bucket下面多了一个Key)
所以可以看出,尽管用户只上传了一个几百字节的文件,甚至还没有一个sector大,但是ceph的多个osd都要发生写操作。如果这是一个大文件,比如4M,这些overhead就完全可以忽略。文件越小,数量越大,硬盘的随机读写越多。
这种情况在filestore的情况尤其糟糕,filestore所有的写入都先写入自己的journal,然后在fflush到文件系统。这种情况在bluestore会好一些,因为S3的写入都是新文件,没有覆盖或者更新的情况,所有不用写journal,数据直接落盘。2.3 ceph在rebalance时,对在线环境是否影响很大
简单的回答:很大
更精确的回答:主要跟迁移的数据量有关,迁移的数据量越大,影响也越大。
在线上一个50台服务器的EC集群上,万兆网络,容量超过50%,当掉一台服务器(需要迁移6T数据),并且在默认的迁移线程个数的情况下,新的写入IO速度只有原来的10%。这时运维工程师通常的选择是暂停rebalance,保证线上业务,在业务不忙的情况下,比如凌晨继续迁移。
但是在停止rebalance的情况下,有部分pg处于degrade的状态,比预想的副本数要少。但通常我们为了保证最优的数据可靠性,希望rebalance尽快完成,越快越好。此时的想法又和数据的可用性发生矛盾,是为了数据可用性停服rebalance?还是为了数据可靠性降低可用性损失性能?在线上运维时,掌握这2点的平衡非常困难。2.4 radosgw如何提升性能
线上在使用ceph时还有其它的优化空间,远远不是调试ceph的参数那么简单,如:
1) 提升.rgw,.rgw.index 这些关键元数据pool的性能
元数据的重要性毋庸置疑。
从容量上看,元数据需要的容量很小。如果在集群容量不足的情况下,可以采用元数据3副本,.buckets 2副本或者EC的策略。
从性能上看,提升元数据的存取速度可以极大的提升,所以通常都会把元数据的pool放到纯SSD或者SAS盘的存储介质上。
2) 辅助功能外移,如日志和统计容量
我们在线上关闭radosgw的usage功能,也关闭了bucket index log(我们也不需要multi site)功能,本质上的思路就是在核心的读写流程上面减少环节,从而提升速度。比如日志统计之类的,都可以异步的把radosgw的日志推送到spark集群计算。
3) 更好的cache
有些元数据是需要频繁访问的,比如用户信息,bucket的元数据,这些信息都需要radosgw做cache,但是由于radosgw之间不能直接通信,无法做invalid cache的操作,导致cache的效率不高。社区的做法是利用共享存储(这里就是ceph的一个object),通过这个object通信,就可以打开cache. 这种情况在大流量的情况下,性能非常糟糕,我们在线上已经关闭了这个cache。
3. YIG设计
设计一个新的存储系统解决以上问题,无非这些思路
a.隔离后台rebalance影响
b.根据haystack的论文,默认的filestore或者bludestore,并不特别适合小文件存储,需要新的存储引擎
c.radosgw对librados提高的omap和cls用得太重,我们如何简化架构,让代码更容易懂,也更不容易出错。
d.更加统一的cache层,提高读性能
架构如图所见:从整体看,分为2层
1) S3 API layer,负责S3 API的解析和处理。所有元数据存储在hbase中,元数据包括bucket的信息,object的元数据(如ACL、contentType),multipart的切片信息,权限管理,BLOB Storage的权值和调度,同时所有的元数据都cache在统一的cache层。这样可以看到所有元数据都存储在hbase中,并且有统一的cache,相比于radosgw大大提高的对元数据操作的可控性,也提高了元数据查询的速度。
2) BLOB Storage层,可以并行的存在多个Ceph Cluster。只使用 rados_read/rados_write的API。如果其中一个ceph cluster正在做rebalance,可以把它上面所有写请求调度到其他ceph集群,减少写的压力,让rebalance迅速完成。从用户角度看,所有的写入并没有影响,只是到这个正在rebalance的ceph cluster上的读请求会慢一点儿。这种设计使得大规模扩容也变得非常容易,比如:初期上线了5台服务器做存储,使用过程中发现容量增加很快,希望扩容到50台,但是在原ceph集群上一下添加45台新服务器,rebalance的压力太大。在yig的环境中,只要新建一个45台的ceph集群,接入yig的环境就行,可以快速无缝的灵活扩充。
4.1 在Ceph层提升性能
1)使用libradosstriper API提升大文件读取写入性能
对于大文件,相比于radosgw每次使用512K的buf,用rados_write的API写入ceph集群,yig使用动态的buf,根据用户上传的速度的大小调整buf在(512K~1M)之间。并且使用rados striping的API提高写入的并发程度。让更多的OSD参与到大文件的写入,提高并发性能。拆分方法如图:
2)使用kvstore提升小文件存储性能
针对小文件,直接使用kvstore存储,底层使用rocksdb,这个方案相比于bluestore或者filestore更轻。性能更好。但是要注意2点:
a. 默认的kvstore并没有打开布隆过滤器,需要在ceph的配置文件中配置打开,否则读性能会很差
b. 在Ceph的replicatePG层,每次写object之前,都会尝试读取原object,然后再写入。这个对于rbd这种大文件的应用影响不大,但是对于小文件写入就非常糟糕。所以我们在rados的请求中加入的一个新的FLAG: LIBRADOS_OP_FLAG_FADVISE_NEWOBJ,在replicatedPG中会检查是否有这个FLAG,如果有,就不会尝试读取不存在的小文件。通过这个patch,可以极大的提升小文件的写入性能和降低cpu的利用率。